作者: insightcodeyk
出处: https://insightcodeyk.github.io/2018/04/19/HashMap/
声明: 本文采用以下协议进行授权: 自由转载-非商用-非衍生-保持署名|Creative Commons BY-NC-ND 3.0,转载请注明作者及出处。
1 HashMap存储结构
1.1 重要成员变量
1.transient Node<K,V>[] table;//Hash桶数组
这是以key为index的数组,也就是说这个数组的就是HashMap键值对的物理结构
2.int threshold;//table数组所能容纳的上限值,超过就会调用resize(). (threshold = capacity * load factor).
3.finale float loadFactor;//装载因子
设置的table数组的容量比例,超过容量比例就会扩容,扩大为原来的两倍。设置装载因子的目的是提高HashMap查找效率
4.static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认装载因子
若初始化没有指定装载因子,则默认使用0.75为容量比例。
5.static final int TREEIFY_THRESHOLD = 8;//链表上限
在重复的Key链表节点超过TREEIFY_THRESHOLD之后对Key链表节点结构进行重构为红黑树
6.static final int UNTREEIFY_THRESHOLD = 6;//红黑树下限
当红黑树节点小于等于6时,红黑树重构为单链表
7.staitc final int MIN_TREEIFY_CAPACITY = 64;//扩容和红黑树化的阈值
当table数组容量大于等于64时,哈希桶节点增加超过8则进行红黑树化,否则进行扩容
1.2 HashMap存储组织结构
HashMap中的存储结构,Hash桶数组的结构如下图: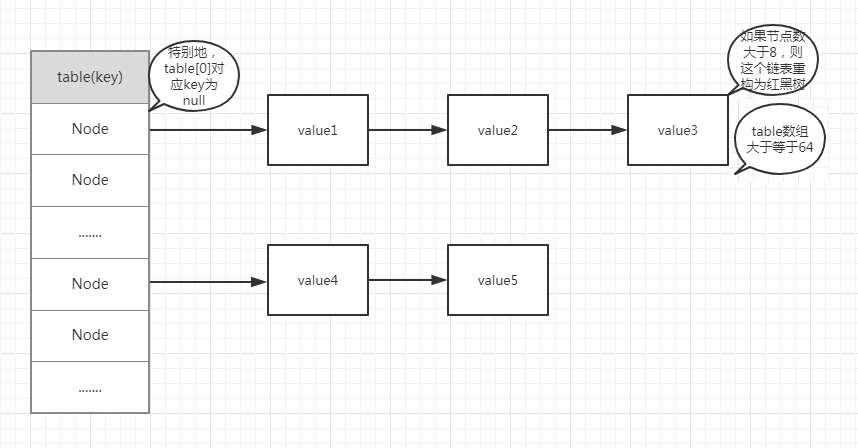
通过这个结构图可以通过几个简单的要点罗列对HashMap的组织结构有一个直观的认知:
1.HashMap维护一个数组table
2.table的index是由HashMap定义的hash算法根据传入的key对象计算出
3.HashMap使用链地址法
4.当链长度小于等于8时,相同Index的键值对以单链表形式存储;当链大于8时,若table长度大于等于64,则相同Index的键值对组织形式重构为红黑树;否则进行resize()
2 HashMap实现要点
理解HashMap的实现方式有三个要点: